
The past half a decade has seen an exponential rise in computing. Applications have far outgrown the client-server model, and distributed computing has become the norm. Kubernetes on AWS offers one of the most powerful distributed computing platforms. Thanks to technologies like Amazon Fargate and the vast outreach of Amazon’s cloud computing infrastructure, the Elastic Kubernetes Service, or EKS, can offer a truly distributed environment where your applications can run and scale, so we will cover a AWS Kubernetes tutorial.
Setting up Kubernetes with AWS with the help of the AWS web console is probably not the quickest way to get started. In the following chapters we will distill down the most straightforward path you can take to launch a Kubernetes on AWS, then we will launch a Dockerized application on this cluster.
Table of contents
- Prerequisites for Kubernetes on AWS
- Why Docker? Didn’t Kubernetes drop Docker Support?
- Kubernetes vs EKS on Amazon
- Anatomy of an Amazon EKS Cluster
- Creating an Amazon EKS Cluster
- Dockerizing your Application
- Deploying the Application
- Conclusion of Kubernetes on AWS
- FAQs
Prerequisites for Kubernetes on AWS
Before we get started with Kubernetes on AWS tutorial, let’s get familiar with a few key concepts. These include:
- An understanding of Docker containers. We will later blur the lines between containers and VM, so make sure you know what’s the difference between a container and a traditional virtual machine.
- Familiarity with AWS related terminologies like IAM Roles, VPCs.
Read our blog about the Top AWS Benefits
Why Docker? Didn’t Kubernetes drop Docker Support?
Kubernetes is a container orchestration engine. To deploy your application to a Kubernetes cluster, you need to package it as one or more container images. Docker is by far the most popular way of working with containers. It helps you:
- Run containers locally on your Windows, macOS, or Linux workstation
- Package your application as a Docker image
Since its conception, Kubernetes has come a long way. Initially, it worked with container runtimes like Docker (which is most common) and rkt. This means each Kubernetes node would have docker installed and running on it. The kubelet binary running on a node would then talk to the Docker engine to create pods, containers managed by Kubernetes.
Recently, the Kubernetes project has dropped support for Docker Runtime. Instead, it uses its own Container Runtime Interface (CRI), and this cuts the extra dependency of having Docker installed on your nodes.
However, it has led to a misconception that Docker is old or incompatible for people who want to learn about Kubernetes.
This is not true. You still need Docker to run and test your images locally, and any Docker image that works on your Docker runtime will work on Kubernetes too! It is just that Kubernetes now has its lightweight implementation to launch those Docker images.
Read our Kubernetes vs Docker blog to learn more.
What are the benefits of using Kubernetes on AWS compared to other cloud providers?
- Complexity: Bootstrapping your Kubernetes cluster is a bad idea. You will be responsible for securing and managing your application, as well as the cluster, networking, and storage configuration. Kubernetes maintenance also involves upgrades to the cluster, the underlying operating system, and much more.
Using AWS’ managed Kubernetes service (EKS) will ensure that your cluster is configured correctly and gets updates and patches on time. - Integration: AWS’ EKS works out of the box with the rest of Amazon’s infrastructure. Elastic Load Balancers (ELB) are used to expose services to the outside world. Your cluster uses Elastic Block Storage (EBS) to store persistent data. Amazon ensures that the data is online and available to your cluster.
- True Scalability: Amazon EKS provides far better scalability than self-hosted Kubernetes. The control plane makes sure that your pods are launched across multiple physical nodes (if you so desire). If any of the nodes go down, your application will still be online. But if you manage your own cluster, you will have to ensure that different VMs (EC2 instances) are on different availability zones. If you can’t guarantee that, then running different pods on the same physical server won’t give you much fault tolerance.
- Fargate and Firecracker: VM instances run on virtualized hardware, i.e, software pretending to be hardware. This results in a better overall cloud infrastructure security. But this comes at the price of slower performance due to a layer of software that is virtualizing hardware resources. On the other hand, containers are lightweight as they all run on the same operating system and share the same underlying kernel. This results in faster boot times, and no performance impact! Running containers directly on the hardware is referred to as containers on bare metal.
At the time of this writing, Amazon is one of the very few public clouds that offers bare-metal containers. That is, instead of launching EC2 instances and then running your containers within those VMs, you can use Amazon Fargate and run the containers on bare metal.
They manage this via Firecracker, a very lightweight Linux KVM-based technology that runs Docker containers inside a microVM. These provide you with the performance of containers and the security of VMs. This alone is the reason why EKS on Amazon is preferable over any of its competitors.

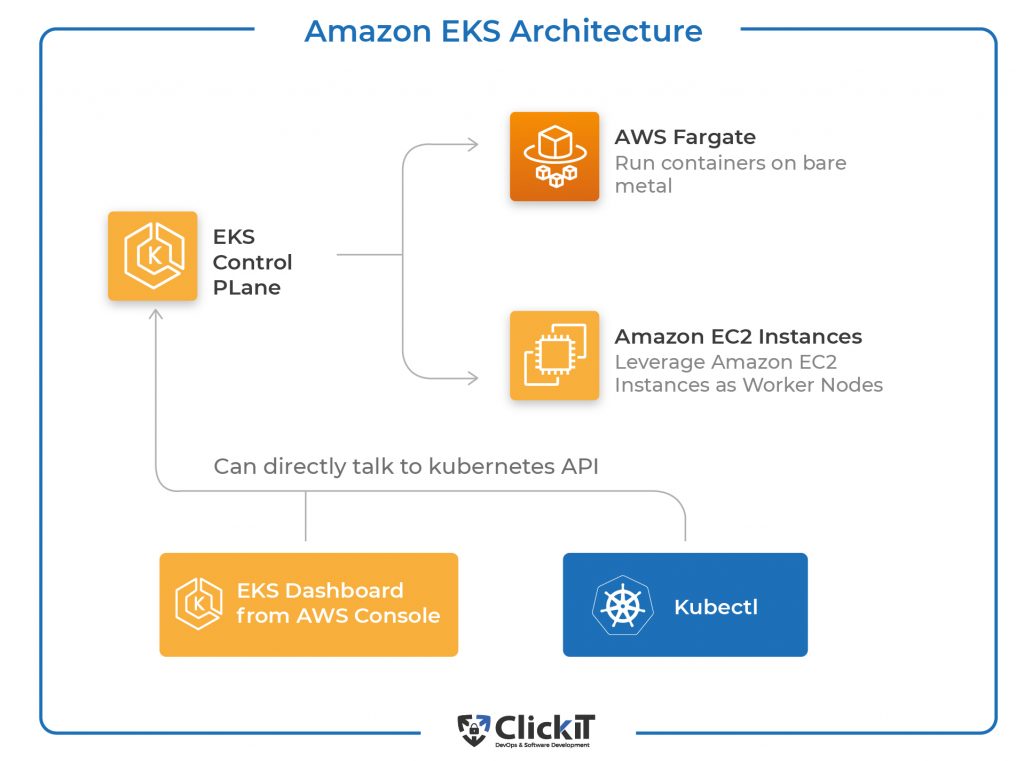
Anatomy of an Amazon EKS Cluster
An EKS cluster consists of two broad components:
- The Control Plane: This service is entirely managed by AWS, as in you WILL NOT have EC2 instances created in your account, where you may expect etcd, kube-apiserver, and other components to show up. Instead, all of that is abstracted away from you, and the control plane is just exposed to you as a server, i.e., the kube-api. The control plane costs $0.10 per hour. Fortunately, you can use a single cluster to run multiple applications, and this price will not go up as you launch more apps or services.
- The Nodes: These can, in turn, be managed EC2 instances or run upon AWS Fargate. Managed EC2 instances option is where AWS spins up EC2 instances on your behalf and gives the Control Plane control over those instances. These show up as EC2 instances in your account. Standard EC2 pricing applies for these Nodes.
In the case of AWS Fargate, there are no EC2 instances to be managed; instead, your pods run on bare metal directly, and you only pay for the time for which the pods run. I highly recommend using AWS Fargate for your new clusters, and we will be also using this in the next section where we create a cluster. The AWS Fargate pricing details can be found here.
How to Create a Kubernetes Cluster on AWS?
Now , let’s start with the AWS Kubernetes tutorial. The easiest way to get started with EKS is to use the command-line utilities that include:
- AWS-CLI to interact with your AWS account
- eksctl to create, manage and delete EKS clusters, and
- kubectl to interact with the Kubernetes Cluster itself.
- docker to create and containerize your application.
- Docker Hub account to host your Docker images (free tier will work)
These are the requirements that you need on your local computer for the AWS Kubernetes tutorial.
1. Setting Up AWS CLI
AWS provides users with a command-line tool and the possibility to provision AWS resources straight from the terminal. It directly talks to the AWS API and provisions resources on your behalf. This eliminates the need to manually configure EKS Cluster or other resources using the AWS Web Console. Automating it with CLI also makes the process less error-prone. Let’s set up AWS CLI on our local computer.
1. First, get the CLI binaries suitable for your system.
2. AWS CLI allows you to quickly and programmatically create resources in AWS’ cloud without having to mess around in the dashboard. This eliminates human errors as well.
3. In order to create and manage EKS Clusters you need to be either the root user or an IAM user with Administrator access.
4. I will be using my root account for the sake of brevity. Click on your Profile on the top right corner in your AWS Web Console and select “My Security Credentials”.
Next, navigate to the “Access Keys” Tab in the main menu:

And click on the “Create New Access Key” button.
Then Click on “Show Access Keys” in the new pop-up, and carefully copy both the Access ID and Secret Access Key to your local computer. It is important to note that the secret access key will be shown only once.
5. Open up your terminal and type in the following command and when prompted, enter your Access Key ID and Secret Access Key:
$ aws configure
AWS Access Key ID [None]:
AWS Secret Access Key [None]:
Default region name [None]:us-east-2
Default output format [None]: text
You will also be asked to select a default region. We are going with us-east-2, but you can pick the region that benefits you the most (or is closest to you). And the default output format is going to be text in our case.
Your configuration and credentials live in your HOME directory in a subdirectory called .aws and will be used by both aws and eksctl to manage resources. Now, we can move on to creating a cluster.
2. Creating and Deleting an EKS Cluster using Fargate
To create a cluster with Fargate Nodes, simply run the following command:
$ eksctl create cluster --name my-fargate-cluster --fargate
That is it! The command can take around 15-30 minutes to finish, and as it runs, it will output in your terminal all the resources that are being created to launch the cluster.
You can see a sample output below:
2021-08-01 18:14:41 [ℹ] eksctl version 0.59.0
2021-08-01 18:14:41 [ℹ] using region us-east-2
2021-08-01 18:14:42 [ℹ] setting availability zones to [us-east-2c us-east-2a us-east-2b]
2021-08-01 18:14:42 [ℹ] subnets for us-east-2c - public:192.168.0.0/19 private:192.168.96.0/19
2021-08-01 18:14:42 [ℹ] subnets for us-east-2a - public:192.168.32.0/19 private:192.168.128.0/19
2021-08-01 18:14:42 [ℹ] subnets for us-east-2b - public:192.168.64.0/19 private:192.168.160.0/19
2021-08-01 18:14:42 [ℹ] nodegroup "ng-5018c8ae" will use "" [AmazonLinux2/1.20]
2021-08-01 18:14:42 [ℹ] using Kubernetes version 1.20
2021-08-01 18:14:42 [ℹ] creating EKS cluster "my-fargate-cluster" in "us-east-2" region with Fargate profile and managed nodes
2021-08-01 18:14:42 [ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial managed nodegroup
2021-08-01 18:14:42 [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-east-2 --cluster=my-fargate-cluster'
2021-08-01 18:14:42 [ℹ] CloudWatch logging will not be enabled for cluster "my-fargate-cluster" in "us-east-2"
2021-08-01 18:14:42 [ℹ] you can enable it with 'eksctl utils update-cluster-logging --enable-types={SPECIFY-YOUR-LOG-TYPES-HERE (e.g. all)} --region=us-east-2 --cluster=my-fargate-cluster'
2021-08-01 18:14:42 [ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "my-fargate-cluster" in "us-east-2"
2021-08-01 18:14:42 [ℹ] 2 sequential tasks: { create cluster control plane "my-fargate-cluster", 3 sequential sub-tasks: { 2 sequential sub-tasks: { wait for control plane to become ready, create fargate profiles }, 1 task: { create addons }, create managed nodegroup "ng-5018c8ae" } }
2021-08-01 18:14:42 [ℹ] building cluster stack "eksctl-my-fargate-cluster-cluster"
2021-08-01 18:14:44 [ℹ] deploying stack "eksctl-my-fargate-cluster-cluster"
2021-08-01 18:15:14 [ℹ] waiting for CloudFormation stack "eksctl-my-fargate-cluster-cluster"
2021-08-01 18:46:17 [✔] EKS cluster "my-fargate-cluster" in "us-east-2" region is ready
As the output suggests, a lot of resources are being spun up. Including several new private subnets for the availability zone chosen, several IAM roles and the Kubernetes Cluster’s control plane itself. If you don’t know what any of these are, don’t panic! These details are eksctl’s problem. As you will see when we delete the cluster with the following command:
$ eksctl delete cluster --name my-fargate-cluster
2021-08-01 23:00:35 [ℹ] eksctl version 0.59.0
## A lot more output here
2021-08-01 23:06:30 [✔] all cluster resources were deleted
This will tear down the cluster, remove all the node groups, private subnets, and other related resources, and it makes sure that you don’t have resources like ELB lying around, costing you extra money.

Dockerizing your Application
Now we know how to create and destroy a cluster with the AWS Kubernetes tutorial, But how do we launch an application inside it? The first step of the process is to containerize your application.
To containerize your application, you need to know how to write a Dockerfile for it. A Dockerfile is a blueprint for your container orchestration system to build your Docker image.
What do you need to write a Dockerfile?
- Choose a base image. You can use Docker images for Node or Python, depending on your application’s dependencies.
- Select a working directory within the container.
- Transfer your project’s build artifacts (compiled binaries, scripts, and libraries) to that directory
- Set the command for the launched container to run. So, for example, if you have a node app with the starting point app.js you will have a command CMD [“node”, ”app.js”] as the final line in your Dockerfile. This will launch your app.
This Dockerfile lives in the root of your project’s git repo making it easy for CI systems to run automated builds, tests, and deployments for each incremental update.
Let us use a sample app written in Express.js to be used as a test project to be dockerized and deployed on our EKS cluster.
An Example App
Now, in the AWS Kubernetes tutorial, let’s create a simple express.js app to be deployed on our cluster. Create a directory called example-app:
$ mkdir example-app
Next, create a file called app.js that will have the following contents:
const express = require('express')
const app = express()
const port = 80
app.get('/', (req, res) => {
res.send('Hello World!\n')
})
app.listen(port, () => {
console.log(`This app is listening at http://localhost:${port}`
})
This app.js application is a simple web server that listens on port 80 and responds with Hello World!
Creating a Dockerfile
To build and run the app as a container, we create a file called Dockerfile in the example-app directory with the following contents inside it:
FROM node:latest
WORKDIR /app
RUN npm install express
COPY app.js .
CMD ["node", "app.js"]
This will instruct the Docker engine to build our container using the node:latest base image from Docker Hub. To build the Docker image run the below command:
$ docker build -t username/example-app
Here the tag username needs to be replaced with your actual Docker Hub username. We will discuss why this is the case in the section about Container Registries.
Running the Application Locally
Once the image is built, we can test if it works locally. Run the below command to launch a container for this AWS Kubernetes tutorial:
$ docker run --rm -d -p 80:80 --name test-container username/example-app $ curl http://localhost Hello World!
This seems to be working as intended. Let’s see what the container logs say. Run the docker log command with the specific container’s name:
$ docker logs test-container
This app is listening at http://localhost:80
As you can see, whatever our express.js app was writing to standard output (using console.log) gets logged via the container runtime. This helps debug your application both during testing and in production environments.
About Container Registries
Docker images, by default, are hosted on Docker Hub. Docker Hub is like a GitHub for your Docker images. You can version your images, tag them and host them on Docker Hub
The node:latest tag implies that the latest released version of Node.js will be used for this image’s build process. There are other tags available for specific versions of Node.js such as an LTS release. You can always visit a specific image’s Docker Hub page and look at the various options that are available for you to download.
Just as with GitLab and GitHub, there are various container registries that you can use. AWS has their Elastic Container Repository or ECR solution, GCP has something similar but we will stick to Docker Hub for this article since it is the default for your Docker installation anyways.
To push the image that was built in the previous step, we first login to our Docker Hub account:
$ docker login
And supply your username and password when prompted.
Once you have successfully logged in, push your image with this command:
$ docker push username/example-app
Now the example-app Docker image is ready to be used by an EKS cluster.

Deploying the Application for Kubernetes on AWS
In the AWS Kubernetes tutorial, deploy the application we just built; we will use kubectl, a command-line tool to interact with a Kubernetes Control Plane. If you have used eksctl to create your cluster, kubectl is already authenticated to talk to your EKS cluster.
We will create a directory called eks-configs, which will store a description of the desired state of our cluster and the application running on it.
$ mkdir eks-configs
Creating Deployment
To deploy the app we will create a Kubernetes workload of type Deployment which is ideal for stateless applications. Create a file example-deployment.yaml and add the following to it.
The image being used is username/example-app from Docker Hub. Make sure to replace ‘username’ with your actual Docker Hub username. When this app is run
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
labels:
app: example-ap
spec
replicas: 6
selector:
matchLabels:
app: example-ap
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: username/example-app
ports:
- containerPort: 80
Using kubectl we can launch this deployment as follows:
$ kubectl create -f example-deployment.yaml
This creates a Deployment object, which is Kubernetes’ way of logically handling an application (or a part of an application) that would run on one or more Pods. Next, we added some metadata including the name of the deployment and labels which are used by other parts of our cluster as we will soon see. Also, we are asking EKS to launch 6 replicas of the example-app container to run across our cluster. Depending on your needs you can change that number on the fly- it will allow you to scale your application up or down. Having many replicas also assures high availability since your pods are scheduled across multiple nodes.
Use the following commands to get a list of your deployments and the pods running on your cluster (in the default namespace):
$ kubectl get pods
$ kubectl get deployments
Creating a Service
The deployment is created, but how do we access it? Since it is running across multiple pods how does another application (like a user’s browser) access it? We can’t have direct DNS entries pointing at the pods since they are ephemeral and fungible. Also directly exposing internal components of a cluster to the outside world is not the most secure idea.
Instead, we will create a Kubernetes service. There are several types of Kubernetes services, you can learn about them here. We will be using AWS’ Elastic Load Balancer, or ELB, service for now.
As a side note, this is a general theme with most of the Kubernetes features. They integrate very well with the underlying Cloud Infrastructure. Examples of this include using EC2 instances for nodes, ELB for exposing services to the outside world, AWS’ VPC for networking within the cluster and Elastic Block Storage for highly available persistent storage.
We can create a Kubernetes service of type LoadBalancer by creating an example-service.yaml file and add the following contents inside it:
---
apiVersion: v1
kind: Service
metadata:
name: example-service
spec:
type: LoadBalancer
selector:
app: example-app
ports:
- protocol: TCP
port: 80
targetPort: 80
And then create it using the following command:
$ kubectl create -f example-service.yaml
The Kubernetes Service will be up and running in a few minutes and we can finally talk to our application. To start things off we first need to get the “EXTERNAL-IP” of the service. This is usually not an IP but an FQDN pointing at our service as shown below
$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE example-service LoadBalancer 10.100.88.189 a78b55c6b3a574e61accfe13b324bd08-1728675516.us-east2.elb.amazonaws.com 80:31058/TCP 5m33 kubernetes ClusterIP 10.100.0.1 <none> 43/TCP 33m
The service can be easily accessed from your web browser or by using command-line tools like cURL as shown below
$ curl
a78b55c6b3a574e61accfe13b324bd08-1728675516.us-east-2.elb.amazonaws.co
Hello World!
That is it! You can now start rolling out your application piece by piece to the AWS EKS platform. Keep the number of clusters to a minimum to lower costs and separate different parts of your application into different Dockerized microservices.
Clean Up Kubernetes on AWS
Know to end the AQS kubernetes tutorial, clean up the resources we previously had, we will delete each Kubernetes resource in reverse order of how we created them and then the entire cluster.
$ kubectl delete -f example-service.yaml
$ kubectl delete -f example-deployment.yaml
$ eksctl delete cluster --name my-fargate-cluster
Double-check that no resources are left by visiting the web UI. For both EKS and EC2 services switch the region in the web UI to ~/.aws/config and make sure you don’t have any unused ELB/EC2 instances or Kubernetes clusters lying around.

Conclusion of Kubernetes on AWS Tutorial
If you are considering a managed Kubernetes solution, running Kubernetes on AWS is about as good as it gets, as you see in the AWS Kubernetes tutorial. The scalability is outstanding, and the upgrade process is smooth. The tight integration with other AWS services that you get by running Kubernetes on AWS is also a huge bonus.
Implementing the AWS Kubernetes tutorial would free your company from the hassle of managing the infrastructure and give you more time to focus on the core product. It would reduce the need for additional IT staff and, at the same time, enable your product to fulfill an ever-increasing demand from your user base.
Kubernetes on AWS FAQs
Kubernetes on AWS abstracts away a lot of complexity of managing Kubernetes. The process of creating, upgrading and scaling the cluster is smooth and easy.
At the same time, Kubernetes on AWS takes advantage of AWS’ vast array of data centers to allow you to scale across the globe.
In short, you want to run Kubernetes with AWS because:
1. It frees up human resources to work on your actual product and not busy themselves with managing Kubernetes
2. It allows you to scale across AWS’ vast infrastructure
3. Running Kubernetes on AWS allows you to easily integrate with a lot of other AWS services like ELB to expose services, EBS to store persistent data and CloudWatch for logging.
The control plane for each Kubernetes Cluster you create costs you $0.10 per hour, which is $73 per month. You don’t have to create a new cluster for each new application. Instead, it is recommended that you use Kubernetes Security Policies and IAM Roles to multiple applications on your Kubernetes Cluster. So the control plane cost is static.
In addition to that, you pay the standard EC2 prices for worker nodes, even if EKS manages them. The EC2 pricing details can be found here. The pricing is pay-as-you-go so you don’t have to worry about upfront payments or minimum amount.
If you are using AWS Fargate, as we did, this price can go down significantly. You only pay for the vCPU and memory used by the pods from the time your application runs. This means starting from the time you run kubectl create -f app.yaml to the point where pods are terminated.
On top of this, you pay for other resources like ELB resources if you spin up LoadBalancers for your Kubernetes services. Similarly, using EBS for persistent data will cost you extra.
If you think Kubernetes isn’t the right fit for you, you can always go for Elastic Container Services (ECS). This is an alternative solution to run your containerized workload on the cloud without having to worry about the underlying servers.
Similarly, for stateless apps, AWS Lambda is a good choice and it works seamlessly with other AWS services like S3, DynamoDB, Route 53 allowing you to extend the functionality of your functions.
This post (link the heading “Creating an Amazon EKS Cluster” here) covers the simplest way to deploy Kubernetes on AWS.
AWS, or Amazon Web Services, is a cloud computing platform provided by Amazon. Essentially, it is a service that allows you to run your web applications (like websites, databases, etc) on Amazon’s servers and just pay for the time and compute resources that you consume.
Kubernetes is an open-source technology that allows you to leverage cloud computing platforms like AWS. When you run Kubernetes with AWS, you spread out your application across multiple computers. If any of them encounter a failure, Kubernetes will ensure that your application is still online and served by the other computers.
Kubernetes also allows you to scale your application. For example, if the traffic to your website increased by 10 times, you can easily use Kubernetes on AWS to provide more computers to handle the additional load. You can scale it down when the traffic decreases.




