
SRE vs DevOps salary, background, and roles are similar to a great extent, which creates a lot of confusion. Since DevOps revolutionized the software development landscape, a wide variety of processes, practices, and job profiles have risen. Therefore, let’s the Site Reliability Engineer vs DevOps popular topic. Are they really different?
The DevOps engineer will improve your site’s speed and agility, while a Site Reliability Engineer focuses on its availability and reliability. A DevOps expert can handle both jobs in smaller organizations, but larger teams need to decipher their differences and, most importantly, build a strong collaboration between the SRE and DevOps engineer roles rather than compete with each other. This blog unravels the nuances associated with the Site Reliability Engineer vs DevOps debate. Let’s get into it!
- SRE vs DevOps: What is DevOps?
- What is a DevOps Engineer?
- What are the Roles and Responsibilities of a DevOps Engineer?
- SRE vs DevOps: What is a Site Reliability Engineer (SRE)?
- What are the responsibilities of a Site Reliability Engineer (SRE)?
- What are the differences between an SRE vs DevOps Engineer?
- SRE vs DevOps: DevOps Tools
- SRE vs DevOps: SRE Tools
- SRE vs DevOps Same Tools, Different Usage
- SRE vs DevOps Tools
- Conclusion
- SRE vs DevOps FAQs
Site Reliability Engineer vs DevOps Video
What is DevOps?
DevOps is a methodology that integrates and automates development and operations while introducing a DevOps culture to deliver quality software faster and better. While the name speaks only about development and operations, other teams are involved, such as Testing/QA, network, compliance and security, and business management.
What is a DevOps Engineer?
A DevOps engineer is responsible for designing the right DevOps architecture across the organization. Right from creating and advocating DevOps culture to designing the right CI/CD pipelines, application infrastructure, and Docker/Kubernetes containers to automating entire processes, managing compliance, and monitoring metrics, a DevOps engineer ensures an efficient and productive software development environment.
A DevOps engineer is an IT professional who uses knowledge of software development, IT operations, and security to monitor and manage software development, infrastructure management, and the DevOps toolchain in an organization. The global DevOps market is estimated to reach USD 25.5 billion by 2028, so it is important to know more about a DevOps engineer or what an SRE does before getting into the SRE vs DevOps debate.
It is important to note that the role and responsibilities of a DevOps engineer vary from organization to organization. In smaller organizations, DevOps engineers play the role of SREs as well, making the SRE and DevOps engineer debate interesting.
Another interesting comparison: DevOps Engineer vs Software Engineer
What are the Roles and Responsibilities of a DevOps Engineer?
- Introduce and advocate DevOps practices and culture across the organization.
- Architect and build the application infrastructure in the cloud.
- Design and implement CI/CD pipelines—creation, optimization, and maintenance of this practice.
- Docker and Kubernetes administration.
- Automate any DevOps task within the application infrastructure using Infrastructure as Code and Python/Bash scripting.
- Security Compliance, DevSecOps, Hardening, and Information Security in general.
- Monitoring and logging (in smaller organizations or for new products).
Watch our video about the Roles and Responsibilities of a DevOps engineer or read a complete guide on hiring a DevOps engineer.

What is a Site Reliability Engineer?
A Site Reliability Engineer focuses on properly integrating software development and operations teams in a more proactive way, thereby ensuring improved system reliability and availability. Not only does the SRE take care of the site’s availability, but they are also responsible for its performance. As such, an SRE emphasizes the operations side, taking care of the incident response, SLAs, performance issues, downtimes, and infrastructure health.
Looking at the discussion on site reliability engineers vs DevOps, one may think they are competing with each other. That is not true. A Site Reliability Engineer (SRE) doesn’t compete with a DevOps engineer, but they both complement each other. The concept of SRE was first introduced by Google in 2003. It was later adopted by Amazon, Netflix, and other enterprise organizations. Ben Treynor Sloss, who is a Vice President of Engineering at Google, is known to have coined this term. This was when the DevOps vs SRE all began.
What are the Roles and Responsibilities of an SRE?
- Ensuring system reliability and availability while proactively implementing strategies for maintaining Mean Time to Recovery (MTTR) at the lowest possible level.
- Partnering with DevOps teams in designing and building software and systems, architectural design, automation, and security at the system/process level.
- Measure the performance of systems and monitor the infrastructure with a holistic view of the system’s health.
- Proactively make changes for continual improvement of systems to align with the changing needs of customers.
- Fixing support escalation issues while empowering systems with self-healing abilities to reduce incidents.
- Efficiently manage on-call rotations and processes for a real-time collaborative response on incident on-call tasks.
- Document historic knowledge gathered from different teams to ensure standardization of workflows and consistency in incident response across the infrastructure.
What are the Differences Between SRE and DevOps Engineer?
A DevOps engineer focuses on speed and agility, while an SRE always looks at the availability and reliability of the site. The roles of SRE and DevOps engineers look similar from a bird’s eye view. However, they both work with different goals in mind.
Here is an example to better understand the SRE vs DevOps roles in reality. Consider an instance wherein the DevOps team is planning to develop and launch a web application. When it comes to the application lifecycle, a DevOps engineer handles the application design, development, and infrastructure configuration.
They also ensure that the app is properly deployed to the production environment and performing as per the defined metrics. In this process, a DE creates cross-functional teams to facilitate shorter and faster release cycles, with every member sharing the responsibility throughout the product life cycle.
An SRE takes over from here and ensures that the infrastructure is properly functioning to enable the application to deliver better performance and high availability. Firstly, the SRE team creates Service Level Objectives (SLOs) to measure the system/site performance. They run the application under normal operating conditions and note down the performance levels and then run it under heavy loads to identify the acceptable performance degradable level.
After that, they prepare Service Level Agreements (SLAs) based on these values. When the team receives a warning that the performance level is getting closer to the SLA value, they immediately respond and revert it to a healthy condition. The SLOs are also used to prioritize reliability work. For instance, fixing performance issues of a service that is not meeting the SLO is prioritized over optimizing the performance of an app running at the SLO level.
SRE vs DevOps Focus
A DevOps engineer focuses on removing silos between teams and facilitates incremental development and shared responsibilities. However, an SRE focuses on what an end-user needs: site reliability and availability.
While a DevOps engineer designs and implements DevOps in an organization, an SRE sustains it to deliver optimal performance always. While the former slightly leans on to the Dev side of DevOps, an SRE loves the Ops side of DevOps. This is where both SRE and DevOps engineer stand in this SRE vs DevOps battle.
DevOps vs SRE Salary – Who Makes the Most?
The salaries of DevOps engineers and Site Reliability Engineers are almost equal. According to Builtin, the average salary of a DevOps engineer in the US is $133,133, while the average salary of an SRE is $129,322.
Though the DevOps vs SRE salary are quite similar, there are slight variations depending on factors like experience, location, and industry. Entry-level DevOps engineers typically earn between $70,000 and $90,000, whereas entry-level SREs usually make between $75,000 and $95,000. Mid-level and senior roles see an increase, with mid-level DevOps engineers earning $100,000 to $130,000 and SREs earning $105,000 to $135,000. Senior DevOps engineers can make $140,000 to $180,000, while senior SREs can earn $145,000 to $185,000.
Geographic location can also impact salaries. For instance, in the San Francisco Bay Area, DevOps engineers can earn between $150,000 and $180,000, while SREs might earn $155,000 to $190,000. Similarly, in New York City, DevOps engineers earn $140,000 to $170,000, with SREs slightly higher at $145,000 to $175,000. Other tech hubs like Austin, Texas, and Seattle, Washington, offer competitive salaries as well, though slightly lower than the top two cities.
Industry also plays a crucial role in determining the DevOps vs SRE salary. Tech giants like Google, Amazon, and Facebook offer higher compensation packages, with DevOps engineers earning $140,000 to $180,000 and SREs earning $145,000 to $190,000. In the finance sector, both roles earn slightly less, while in healthcare, the salaries are lower but still substantial.
Bonuses, certifications, and advanced skills also enhance earning potential, making both career paths very lucrative in the tech industry.
Site Reliability Engineer vs DevOps Engineer Tasks
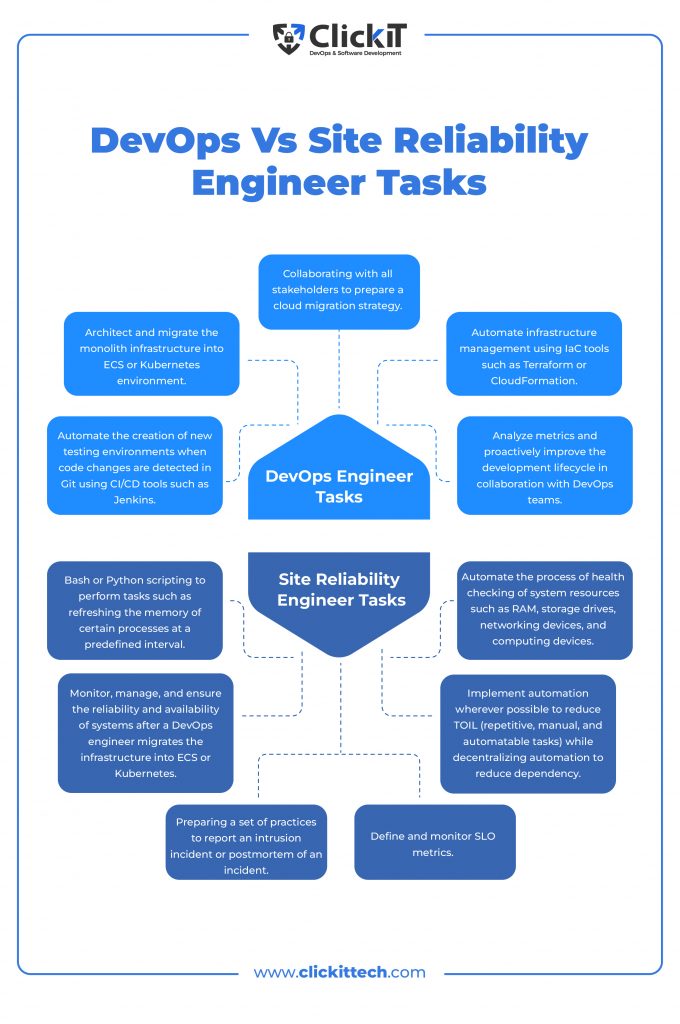
Read our blog DevOps vs Developer
Site Reliability Engineer vs DevOps: DevOps Tools
Linux Administration
Considering the fact that most cloud servers, mobile phones, web servers, and hundreds of operating systems are powered by Linux kernel, knowledge of Linux is a key requirement for DevOps engineers.
Some of the Linux-based tasks include but are not limited to:
- Build and compile code
- Install and configure software
- Run, monitor, and manage applications and processes
- Manage users, groups, and permissions
- Server setup and management
- Configure and manage network firewall and inbound/outbound connections
- Automate wherever possible using scripting tools
While DevOps engineers can use the CLI to perform administrative tasks using commands, GUI tools such as MySQL Workbench, phpMyAdmin, Webmin, Zenmap, and cPanel simplify this process.
Automation with Bash and Python Scripting
Day-to-day administrative tasks are repetitive. For instance, creating a user on multiple servers is repetitive and tedious as well. Automation with Bash or Python scripting on Linux systems reduces time and effort as well as eliminates manual errors.
DevOps engineers can write a script or a shell program comprising a sequence of steps for the system to execute in order to perform specific tasks and rerun it multiple times if needed. A shell script can be 2-3 lines or some thousands of lines based on your task requirement. Shell scripts can perform the installation of new software/hardware, add and remove functions or features, fix bugs, or manage changes that arise from Linux updates.
- Bash Scripting
Bash is a command line interpreter that comes as a replacement for the sh Unix shell to interpret and automate tasks. It comes installed with Linux by default. Bash is best suited for writing smaller scripts. It is simple and easy to use.
- Python Scripting
Python is an OOPs-based high-level programming language that not only offers scripting but can be used for automation and app development. It is best suited for scripts that comprise thousands of lines of code using libraries and objects that perform complex tasks. DevOps engineers might have to install the software separately.
The Cloud
Cloud computing and DevOps complement each other. With the cloud, DevOps engineers can access highly scalable resources to build and deploy new features frequently and securely. And seamlessly collaborate with teams across projects while implementing automation wherever applicable. The cloud makes DevOps implementation simpler and more effective.
Amazon Web Services, Microsoft Azure, and Google Cloud Platform are the three popular cloud providers in the market. While AWS is the leader in this space, Azure and Google are quickly catching up. AWS offers more services than Azure and GCP. It all comes down to your cloud requirement, existing infrastructure, and use cases.
Infrastructure-as-Code (IaC)
Infrastructure-as-Code (IaC) is a practice of provisioning and managing the infrastructure using code and thereby eliminating the tedious, repetitive, and error-prone manual configuration process. Using an IaC tool, DevOps engineers can define infrastructure configuration in a text file and manage the infrastructure always in its desired state. IaC enables a DevOps engineer to version control the infrastructure, better collaborate with teams and ensure that the infrastructure is always maintained in a desired state.
IaC Tools
Terraform, CloudFormation, and Ansible are the three most popular IaC tools available for a DevOps engineer. Here is where the SRE vs DevOps debate gets more interesting. A Site Reliability Engineer uses the same tools but for a different purpose. We’ll discuss this later in the blog.
- Terraform: Terraform is an open-source infrastructure-as-code tool that allows DevOps engineers to use a declarative configuration language called HashiCorp Configuration Language (HCL) to manage the infrastructure. It also supports JSON format. Terraform is a multi-cloud IaC tool that supports all major cloud computing service providers and is free to use.
- AWS CloudFormation: AWS CloudFormation is a cloud computing infrastructure-as-code tool offered by Amazon Web Services. It supports both JSON and YAML formats accommodating both new and advanced DevOps users. CloudFormation is free to use but is primarily focused on AWS services.
- Ansible: Ansible is a software suite comprising tools for resource provisioning, application deployment, and configuration management, offered to customers as Ansible Automation Platform. It is an agentless tool, which means DevOps engineers don’t have to install anything on the system that is being monitored. The fact that Ansible uses YAML for Ansible Playbooks makes the syntax easy to read for everyone compared to JSON or XML formats. It takes an imperative approach to automation and focuses on the entire IT workflow.
For AWS-heavy workloads, CloudFormation is the right choice. Terraform suits multi-cloud environments. For smaller environments, Ansible helps with quick setup and ease of use. Understanding the differences in the Site Reliability Engineer vs DevOps battle is the key here to assign the right people with the right tools.
Read our blog Terraform best practices.

Continuous Integration / Continuous Delivery (CI/CD)
Continuous Integration and Continuous Delivery or Continuous Deployment is a practice of implementing automation into the lifecycle of code development to facilitate frequent and quality code delivery. Using a CI/CD tool, DevOps engineers can automate the code development, deployment, and maintenance process throughout the app life cycle. As such, the organization benefits through faster time to market, better code quality, reduced risks, faster bug resolutions, measurable progress, and efficient management of the infrastructure.
Here are the three popular CI/CD tools for DevOps engineers:
- Jenkins: Being one of the oldest players, Jenkins is preferred for the automation of CI/CD pipelines by many DevOps engineers. This open-source tool offers a versatile ecosystem with hundreds of plugins and higher extensibility. The flexibility and extensibility enable a DevOps engineer to integrate it with other CI/CD tools or quickly create new jobs.
- CircleCI: CircleCI is a popular CI/CD platform that is designed to efficiently manage and scale complex CI/CD pipelines. CircleCI is easy to set up and use. The tool offers built-in plugins to run container-based tasks on Linux or OSX, eliminating the costs for operational overheads and the management of plugins. The fact that it doesn’t require a dedicated server makes it easy for DevOps engineers to set up, run and debug CI/CD tasks. However, CircleCI is only available for GitHub and BitBucket repositories.
- GitLab: GitLab is an open-source CI/CD engine built on Git with enterprise-grade security capabilities. GitLab CI is a robust tool that seamlessly integrates with Docker. Adding and managing jobs is simple and easy. Issue management is easy and effective. However, advanced features are only available for Ultimate users.
Read our blog Gitlab vs Jenkins
Docker and Kubernetes
Containers are a critical part of DevOps workloads. Containerization enables DevOps engineers to package an application along with its dependencies so that it can be seamlessly deployed across various environments without compatibility issues. As such, containerization software and container orchestration tools are important for DevOps engineers. When it comes to Site Reliability Engineer vs DevOps, both share equal responsibilities in this container space.
Docker
Docker Inc. is a leading provider of containerization services for businesses of all sizes. Implementing OS-level virtualization, Docker Engine hosts and manages container deployments in production environments. Being lightweight, Docker enables you to run multiple workloads on a single machine.
When a container is created, Docker makes a set of namespaces to isolate the workspace of that container. As such, DevOps engineers can run multiple containers side by side securely, accessing them via namespaces. It allows them to derive consistent performance from applications across multiple work environments.
Kubernetes
An open-source container orchestration tool that works with containers (industry-standard core container runtime) and CRI-O (Kubernetes container runtime interface based on Open Container Initiative), helping DevOps engineers efficiently manage large cloud-based workloads at scale. Coming from the Internet giant Google and being open-source and free, Kubernetes is a first choice for a DevOps engineer when it comes to managing container-based workloads. Container pods in Kubernetes come with self-healing abilities by default, making it easy for DevOps engineers to handle failovers and backups efficiently.
Read our blog, Docker vs Kubernetes, to learn more about these open sources
Kubernetes on AWS and Azure
AWS makes it easy to run and manage Kubernetes, facilitating easy integrations with a wide array of AWS services. It offers a fully-managed Kubernetes service in the form of Amazon EKS. Alternatively, you can manage Kubernetes using Amazon EC2.
Azure Kubernetes Service (AKS) is a fully-managed cost-effective Kubernetes service offered by Azure. It is quick to update new releases and scale clusters automatically.
What is K8S?
K8S is a short form for Kubernetes. The number ‘8’ refers to the eight alphabets between `K’ and `S’. The name Kubernetes is derived from Greek and means pilot or helmsman.

SRE vs DevOps: SRE Tools
As we get into the specifics of an SRE’s responsibilities, the SRE vs DevOps context will turn into an SRE and DevOps concept.
Application Performance Management tool
APM (Application Performance Management) is about ensuring that apps and the site are available and delivering optimal performance. It is interchangeably used with application performance monitoring. However, application performance monitoring is a part of application performance management.
An SRE uses an APM tool to monitor the application against predefined metrics, collect app performance metrics and analyze them to identify potential issues, and set up a system to alert the concerned people for a quick resolution when the baselines are not met.
SREs use APM tools to perform the following tasks:
- Digital Experience Monitoring
- Application Monitoring
- Database Monitoring
- Availability Monitoring
Popular APM Tools
DataDog, NewRelic, and Kibana are the three most popular APM tools available in the market for SREs.
- DataDog: One of the popular Application Performance Monitoring and Observability services available in the market for SREs. This SaaS-based tool enables SREs to monitor containers, hundreds of OSes, web apps, mobile apps, and cloud hosts while displaying results in visually appealing graphs, charts, and rolling timelines. DataDog shines in the infrastructure management segment.
- New Relic: A widely-used APM tool that enables SREs to monitor the hardware and software performance of service operators as well as user interactions on web and mobile apps. The tool is best suited for monitoring application performance. With rich RESTful APIs, New Relic is highly extensible.
- Kibana: A popular open-source data visualization dashboard software that SREs use with the ElasticSearch analytics engine. Real-time charting and summary of streaming data, an intuitive interface, and flexible visualization options are key features of Kibana that enable SREs to gain insights into application and site performance. It normally comes as a product suite of Elastic referred to as ELK Stack (ElasticSearch + Logstash + Kibana).
- Grafana: A data visualization tool that initially targeted time series databases but quickly evolved to work with relational databases. It enables SREs to monitor the infrastructure using a highly intuitive graphical analytics dashboard. Grafana is cloud-agnostic and seamlessly integrates with a variety of data sources such as Splunk, MySQL, InfluxDB, and Prometheus.
Automated Incident Response Systems
This is a key responsibility of a Site Reliability Engineer that sets them apart in the Site Reliability Engineer vs DevOps similarities. Automated Incident Response Systems help SREs to manage infrastructure with ease. As the name suggests, AIRSs regularly perform vulnerability scans to automatically detect, analyze and generate actionable threat intelligence. As such, SREs can quickly respond to incidents and remediate risks and thereby saving time and costs.
Here are some of the popular Automated Incident Response Systems:
- PagerDuty: PagerDuty is a SaaS-based incident response management service that works as an alarm aggregator, collecting all alarms from monitoring services and tools to provide SREs with comprehensive visibility into infrastructure operations. With a centralized view, SREs can eliminate duplicate alerts, customize and filter alert notifications and reduce time to repair. It supports voice calls, SMS, Push notifications, and emails.
Automated Incident Response Systems features:
- PagerDuty Incident Response: Generates insights to solve and prevent critical incidents
- PagerDuty On-Call Management: Flexible distribution and scheduling of on-call responsibilities across the infrastructure.
- PagerDuty Automation Actions: Keeps respondents and event rules on the same page while diagnosing and remediating issues in production infrastructure.
- PagerDuty RunBook Automation: Easily create self-service IT operations.
- Opsgenie: OpsGenie is a cloud-based incident response management service that enables SREs to integrate multiple monitoring tools and services such that reliable alerts are sent to the right people on every type of device. It is easy to set up and schedule an alerting system for new users as well. Using Python integration, SREs can easily customize alerts. It supports email, calls, SMS, and Push notifications.
- VictorOps: VictorOps is a popular Incident Response Automation platform that now comes with a new name Splunk On-call. It enables SREs to handle the entire incident life cycle with efficiency. Right from detecting and logging the incidents to prioritizing, categorizing, and escalating with response resolution, VictorOps automatically takes care of the incidents to save time and costs. In addition, it offers reporting and documentation with actionable insights for SREs to gain complete visibility into incident management across the infrastructure.
Configuration Management Tools
Configuration management tools automate the previously tedious process of identifying, tracking, and documenting changes in devices, software, and hardware across the infrastructure. Simply put, CM tools allow SREs to maintain every system in its desired state.
Terraform, CloudFormation, and Ansible are the three most popular configuration management tools available for SREs. While DevOps engineers also use the same tools, they focus on IaC tasks, while SREs focus on the change management part.
SRE vs DevOps Same Tools Different Usage
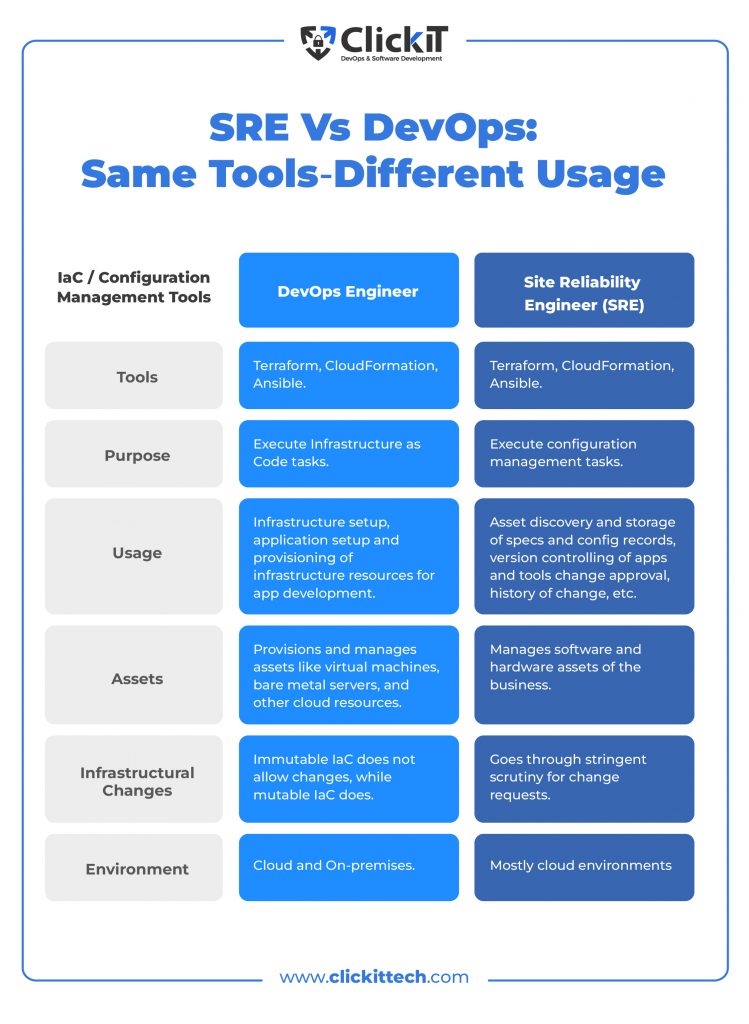
Automation with Bash and Python Scripting
While DevOps engineers use Bash and Python scripting for software development tasks, SREs mostly use them for administration tasks. For instance, a Site Reliability Engineer can write a script to refresh the memory of a specific device at the end of every day or a week, turn off unused VMs or other cloud resources, back up specific data, or perform routine maintenance tasks.

A Unix-based Server / Windows Server
A Site Reliability Engineer mostly deals with infrastructure administration tasks and hence works with massive servers at scale. As such, a thorough knowledge of operating systems is a key requirement for an SRE. Linux is the most popular OS for large networks. As such, an SRE should know different flavors of Unix, such as Ubuntu, Debian, Linux, CentOS, etc.
SRE vs DevOps Tools

Conclusion of SRE vs DevOps
As DevOps evolves, organizations have been getting to know the true potential of this methodology in recent times. Understanding the site reliability engineering vs DevOps differences is key here. For smaller organizations that have 2-6 DevOps engineers, a DevOps engineer performs the tasks of an SRE as well.
Large enterprises wherein 10 or more DevOps engineers are available, divide their tasks between the DevOps engineer and the SRE. Similarly, when they launch a new product, a DevOps engineer will handle the entire product lifecycle initially. After a successful release of the product, the SRE will take over and ensure high availability and reliability. Understanding these subtle and key differences is essential to fully leveraging the future of DevOps. Organizations that fully leverage the role of an SRE are sure to surge ahead of the competition.
SRE vs DevOps FAQs
In a traditional development environment, Dev and Ops have opposite goals and priorities. But an SRE takes a DevOps approach, working with people on shared responsibilities and believing that change is necessary to enhance the quality and performance of the app.
An SRE should have a thorough knowledge of operating systems, databases, distributed system networks, cloud-native application environments, monitoring tools, version control tools, etc. In addition, an SRE should know about coding, CI/CD pipeline, monitoring, and automation. Problem-solving ability and precise communication are important as well.
The salaries of DevOps engineers and Site Reliability Engineers are almost equal. According to Builtin, the average salary of a DevOps engineer in the US is $133,133, while the average salary of an SRE is $129,322.
While a DevOps engineer designs and implements DevOps in an organization, an SRE sustains it to deliver optimal performance. While the former slightly leans on to the Dev side of DevOps, an SRE loves the Ops side of DevOps. This is where an SRE and a DevOps engineer stand in this SRE vs. DevOps battle.
In short, neither SRE nor DevOps is inherently “better” than the other. They serve different purposes:
DevOps emphasizes collaboration and automation across development and operations teams.
SRE focuses specifically on reliability engineering, applying software engineering principles to operations tasks.
Which is better depends on your organization’s needs and goals. Many organizations find success with a hybrid approach that combines elements of both methodologies.




