
Generative AI applies to a new category of artificial intelligence models that create content, such as essays, generate images, compose music, and even programs. Products like ChatGPT and DALL-E exemplify it. These models undergo training on vast amounts of information and subsequently create new data in response to given prompts. It is more complex than just reproduction.
Generative AI Architecture refers to the organized system that underlies a model such as ChatGPT or DALL·E. It begins with data collection and the preparation of high-quality data, followed by the selection or fine-tuning of a generative model for the specific application case. Feedback loops are introduced to make responses better over time.
The model is served through APIs or containers on scalable infrastructure, embedded in real-world applications, and closely monitored for performance, accuracy, and ethics issues. This multi-level structure makes the system pragmatic, trusted, and constantly changing; not merely a model, but an end-to-end smart solution.
At first glance, it might seem like all GenAI projects share the same architecture but that’s not true. In reality, the architecture depends on the specific pattern or approach you choose. From building a foundation model from scratch to simply using prompt engineering, each method comes with its own design, components, and deployment strategy.
In this blog, I’ll walk you through five distinct Generative AI Architecture Patterns used in real-world projects. For each one, we’ll explore when to use it, how it works, and what layers it includes.
Plus, a checklist I personally follow when building or planning any GenAI project. Whether you’re just curious or planning to build your own, I hope this provides a clear and practical starting point.
Key Layers of a Generative AI Architecture
There is a framework of interlinked layers that work in unison to breathe life into a Generative AI System. Be it a chatbot, an image generator or a code assistant, almost every use case falls within the same pattern of GenAI Architecture.
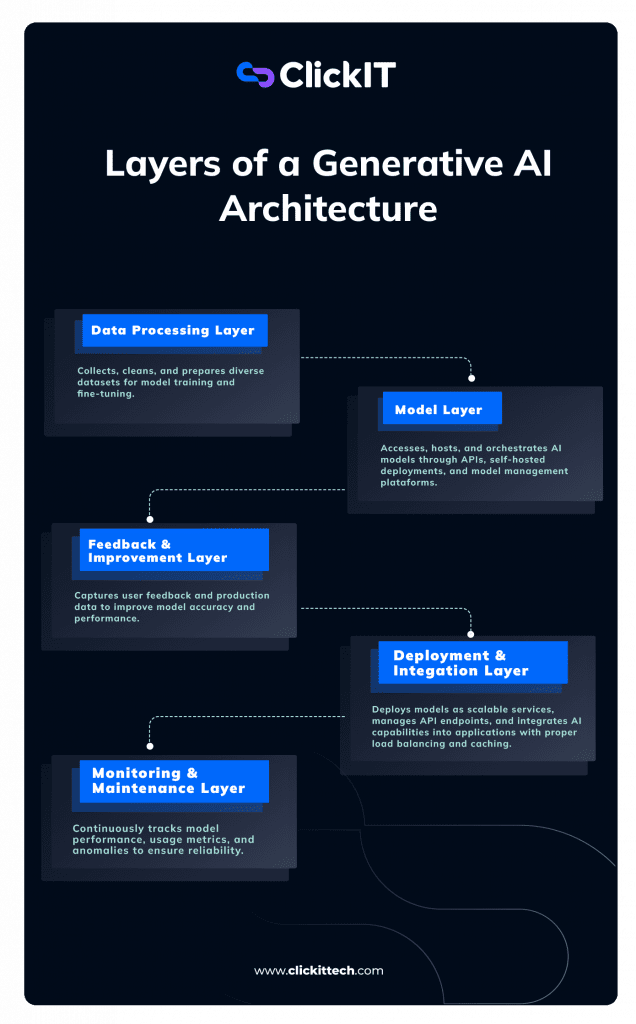
Data Processing Layer
This is where it begins. Everything begins with data, and a lot of it. The quality, relevance, and structure of this data significantly impact the system’s performance. At this stage, raw data is collected, cleaned, formatted, and preprocessed before being passed to the model.
Depending on the application, this may involve tokenizing text, denoising, labeling inputs, or image transformation.
To me, this layer lends tone to the entire system. If the data is disorganized, the output tends to be as well.
Model Layer
When the data is prepared, it’s time to introduce the thinking cap of the system; the model. Depending on the use case, this may involve leveraging pre-trained foundation models, such as GPT, LLaMA, or Stable Diffusion. In other scenarios, these models may be fine-tuned using domain-specific data to better align with the target problem.
From model selection, training, and fine-tuning to prompt engineering and experimentation, this layer is involved.
Feedback & Improvement Layer
Regardless of how well the model is, it can constantly be improved. That’s why a feedback mechanism is essential. This could be something as basic as a user thumbs-up/down, or more sophisticated, such as error logging and retraining based on true-world interactions.
As time passes, this feedback will help refine the system and bring it closer to user expectations.
Deployment & Integration Layer
Since the model’s now trained and feedback-ready, it’s time to deploy. Typically, the model is wrapped in an API, containerized (e.g., using Docker), and hosted on scalable cloud infrastructure. It can then be integrated into web applications, internal tools, or even into messaging platforms.
This is where it transitions from “just a model” to something that actual users can utilize.
Monitoring and Maintenance Layer
Once it’s live, the job isn’t done. It’s also vital to observe its performance, response quality, latency, consumption metrics, and even things that are ethically questionable like bias and hallucination. This also contains logging, alerting, and assessing.
All of these functions contribute to maintaining stability, security, and usefulness.
Here’s a visual breakdown highlighting how data flows across each layer from ingestion to deployment, feedback, and monitoring.
Generative AI Architecture Patterns

Generative AI Architecture Patterns Comparison
| Pattern | Use Case | Training Needed | Data Requirement | Infra Complexity | Time to Deploy |
| Train from Scratch | Enterprise LLM | Full | Massive | High | Month |
| Fine-Tuning | Domain Adaptation | Partial | Medium | Medium | Weeks |
| Retrieval-Augmented Generation (RAG) | Real-time factual QA | None | Structured Docs | Medium | Days |
| RLHF | Human-aligned assistant | Full + Feedback | Human Rankings | High | Months |
| Prompt Engineering | MVP, internal tools | None | Minimal | Light | Hours |
Training A Foundational Model From Scratch
This pattern involves creating a large-scale, proprietary model from bare data employing large amounts of computing power. It is the most compute-intensive of all Generative AI Architecture Patterns and is followed by organizations developing their own foundation models.
When to Use:
As I mentioned earlier, this trend is adopted by larger organizations, such as OpenAI, Google, or Meta, which possess substantial datasets, computing power, and research personnel. You must adopt this method only when:
- You wish to have complete control over the model architecture.
- You have data not available in the public domain.
- You require Proprietary IP.
Architecture Components
- Data Collection and Preprocessing:
Terabyte to petabyte scale multi-modal data (text, image, audio, code) is collected from various sources. The data is preprocessed, duplicates are deleted, and converted into model-ready format. - Distributed Training Infrastructure:
DeepSpeed, Megatron-LM, or FSDP is used to parallelize model training over hundreds to thousands of GPUs. - Training Loop:
The model trains using self-supervised methods such as masked language modeling (for text) or diffusion (for images). - Checkpointing and Evaluation:
Periodic model weight saving and performance metric saving to track training progress and avoid catastrophic failure. - Deployment Layer:
The model is typically deployed via APIs served on huge, scalable cloud infrastructure.
Fine-Tuning A Base Model
This pattern customizes a pre-trained foundation model to perform well on a specific domain or specific task.
When to Use:
Fine-tuning is useful when you want a model that behaves more accurately for your specific domain, such as:
- Legal Assistants
- Financial Advisors
- Medical Q&A Systems
Architecture Components
- Foundation Model Selection:
Start by picking a Pretrained base model like GPT, LLaMA, Mistral, or Falcon. - Domain Data Collection:
Gather data that truly represents real-world scenarios, such as customer inquiries or product descriptions. - Parameter-Efficient Training:
Use techniques like LoRA or QLoRA to fine-tune your model without needing to retrain it from scratch. - Evaluation and Testing:
Ensure that you use separate datasets and human reviewers to evaluate the performance of your model. - Deployment:
Package your fine-tuned model in Docker and deploy it using Kubernetes, Lambda, or any serverless setup.
Retrieval-Augmented Generation (RAG)
This pattern enhances the model’s output by injecting external, relevant documents at inference time.
When to Use:
Use RAG when your use case demands up-to-date knowledge or relies heavily on proprietary data that the model has not seen during training.
- Internal Knowledge Assistants
- Legal Document Search
- Real-time Q&A Bots
Architecture Components
- Input Query Parsing:
Convert user input into embeddings by leveraging models like BERT or the OpenAI Embeddings API. - Vector Database:
Split documents into chunks and write them to a vector database such as FAISS, Pinecone, or Weaviate. - Context Retrieval:
Retrieve the most similar documents in terms of vector similarity. - Context Injection:
Inject the retrieved documents into the input you give to the language model. - Response Generation:
Produce responses that benefit from both pre-trained and retrieved content.
Read our blog Top 10 RAG Techniques
Reinforcement Learning With Human Feedback (RLHF)
This pattern aligns model responses to human values and preferences through reinforcement learning from user feedback. This is one of the more advanced Generative AI Architecture Patterns, particularly easy to apply in model behavior fine-tuning for maximization of human satisfaction. RLHF assists in aligning the model more towards human expectations.
When to Use:
Use RLHF when you want the model’s responses to capture nuanced human preferences:
- Conversational Bots (e.g., ChatGPT)
- Learning Tutors
- Artificial Intelligence Companions
Architecture Components
- Supervised Fine-Tuning:
Train the model first on pairs of human-written inputs and outputs. - Preference Dataset Creation:
Get human labelers to rate alternative model responses to the same input. - Reward Model Training:
Create a smaller model to predict human rewards. - Policy Optimization:
Apply reinforcement learning algorithms such as PPO (Proximal Policy Optimization) to improve the model’s actions. - Evaluation & Feedback Loop:
Collect user feedback on a regular basis and rerun the model training with that feedback.
Prompt Engineering
This model is based on intelligent prompt crafting and limited infrastructure to provide rapid GenAI capability. It is the quickest and easiest among Generative AI Architecture Patterns
When to Use
Use this for:
- MVPs
- Prototypes
- Low-code/no-code Squads
Architecture Components
- Prompt Templates:
Craft zero-shot, one-shot, or few-shot prompts to inform model actions. - Post-Processing Tools:
Include parsing, validation, or guardrails to organize outputs. - Simple Deployment:
Leverage hosted APIs such as OpenAI or Cohere, which are enabled within apps through tools such as LangChain, Zapier, or Flowise.
Read our blog Advanced Prompt Engineering
Checklist and Real-World Example: Steps to Implement a Generative AI Architecture
In this section, we will explore a step-by-step, practical checklist for deploying a Generative AI system, with an actual example demonstrating the checklist in practice. This integration is intended to close the gap between theory and practice, guiding you from idea to operational solution.
Let’s say you are developing a smart assistant for a rapidly growing e-commerce business. Customers receive thousands of questions every day regarding orders, returns, shipping, payments, etc. The support team is overwhelmed. So, the concept is to design a Generative AI assistant that can reply to the majority of these questions quickly and precisely.

Define Objectives & Use Case
Explanation:
Honestly, this is where I always start, and it has saved me from countless headaches. I sit down and really wonder what I am trying to achieve. What is the real problem here? Who is the one who uses this thing? How do I know that it is working? Whether I am making something to write product details or making a chatbot, once I figure out the ‘why’, everything else falls into place.
Example:
In this case, the objective is to alleviate the workload on human agents by responding to repetitive questions using a chatbot, without compromising the tone and accuracy. We wish to automate at least 70–80% of the support chats coming in and maintain high customer satisfaction. That defines the direction of everything else.
Gather & Prepare Data
Explanation:
Here’s the matter: You can have the fanciest model in the world, but if your data is of poor quality, you will get subpar results. I have learned it more than once in a difficult way. I spend a lot of time ensuring that the data is clean, relevant, and really shows what I am trying to solve. Sometimes I am digging through a public dataset, other times I am working with company-specific data that requires careful labeling.
Example:
We gather the previous support chats, help articles, company policies, and product details. Clean this raw data by removing typos, irrelevant chats, and personal information. We also tag it based on intent; order tracking, refunds, cancellations, etc. This organized, well-prepared dataset will form the basis of the assistant’s intelligence.
Select or Build a Generative Model
Explanation:
This is where it becomes exciting (and slightly stressful). Do I go with something like GPT or Stable Diffusion? Fix a small model? Or do I need to make something from scratch? Most of the time, I lean towards existing models until the wheel is really a really compelling reason to reinforce the wheel.
Example:
We might stick with something like OpenAI’s GPT or a fine-tuned open-source alternative like LLaMA. But rather than being solely dependent on pre-trained intelligence, we upgrade it by utilizing an approach known as Retrieval-Augmented Generation (RAG). This implies we integrate the model with our company’s knowledge base to get it to retrieve suitable responses in real time. We further refine the prompts so that the assistant is polite, accurate, and on-brand.
Train & Fine-Tune the Model
Explanation:
Once I pick out my model, I will make it my own. I use whatever techniques make sense- Transfer Learning, Prompt Engineering, Parameter-Efficient Fine-Tuning. The goal is that the model has the right balance between being normal and being smart, while it is really good in my specific task.
Example:
We fine-tune our model using past customer conversations to make sure it understands tone and intent. We also tweak prompts so the assistant always sounds polite, helpful, and on-brand.
Integrate Feedback Mechanisms
Explanation:
I’ve shipped models that looked great in testing but fell apart when real users got their hands on them. Now I always build feedback loops from day one. Simple thumbs up/down, comment boxes, automatic logging of weird outputs – whatever helps me understand how it’s actually performing in the wild.
Example:
We incorporate feedback tools such as thumbs up/down, and an “Escalate to human” feature. We also monitor how frequently users rephrase or re-ask questions. This feedback provides obvious indicators of what’s working and what’s not. With time, we can retrain the model or make adjustments to the prompts based on this data. It’s an endless improvement cycle.
Deploy the Model (Infrastructure)
Explanation:
Time to ship! I usually wrap everything in a clean API, throw it in a Docker container, and deploy to whatever cloud platform makes sense. From there, it can plug into websites, apps, internal tools – wherever it needs to live.
Example:
We enwrap the assistant in an API, containerize it with Docker, and put it on AWS. It’s integrated into the website chat widget, mobile application, and even on WhatsApp. This is where the assistant actually encounters the user; and it has to be fast, reliable, and secure.
Security & Compliance
Explanation:
This one’s easy to overlook but critical. Am I handling user data responsibly? Are the outputs safe? Am I following regulations like GDPR? I’ve seen too many projects derailed because someone forgot to think about this upfront.
Example:
Security cannot be an afterthought because the assistant receives customer inquiries and confidential information. We encrypt all traffic, anonymize data logs, and comply with GDPR and CCPA guidelines. We also apply filters to ensure the model doesn’t respond with anything offensive or factually incorrect. These guardrails keep the brand safe and establish trust with users.
Monitor, Evaluate, and Iterate
Explanation:
Launch is only the start. I’m always checking how everything is running – response rates, errors, patterns in user feedback. I’m also keeping an eye out for the strange things like hallucinations or biased responses. The top systems get better over time rather than sitting there collecting dust.
Example:
We monitor key metrics, including latency, token utilization, escalation rate, and feedback scores. We also set up alerts and dashboards to track performance in real-time. If we detect a decline, such as a decrease in helpful responses, we review and adjust accordingly. The system continues to learn, improve, and evolve with usage.
This framework has become my go-to approach. It’s not perfect, but it’s helped me avoid a lot of the common pitfalls and ship things that work. If you’re diving into this space, think of these as helpful guidelines rather than rigid rules – they’re meant to make your life easier, not harder.
This combined checklist and real-world flow is how I work through GenAI projects, not just in theory, but on real production systems. Each step builds upon the next, and none of them work well in isolation.
If you’re building your first or fiftieth Generative AI product, feel free to use this structure as a flexible guide. Adapt, skip, expand; whatever fits your goals. The important thing is: don’t treat Generative AI as just a model. Treat it as a system.
FAQs about Generative AI Architecture
Generative AI Architecture is the systematic design behind models such as chatbots and image generators. It has layers for processing data, handling the model, deploying, getting feedback, and monitoring. Good architecture guarantees the system is reliable, secure, and scales well.
Not always. Most use cases can be addressed by directly prompting foundation models such as GPT-4 or Claude without fine-tuning. Yet, in the case of domain-specific applications (such as medical or legal content), fine-tuning or Retrieval-Augmented Generation (RAG) can substantially enhance relevance and accuracy.
RAG is a hybrid model in which a model fetches corresponding documents from an external source (such as a vector DB) prior to generating a response. You require RAG when your model isn’t trained on current or proprietary information and you require real-time relevance.
The data processing layer is important. Even existing data tends to require cleaning, formatting, and anonymizing. Quality input data makes a huge difference in the model’s output. Garbage in, and garbage out is more applicable to GenAI than in most fields.




