
The adoption of generative artificial intelligence in businesses has grown rapidly, especially with RAG-based solutions. In this blog, I will explain how running Hugging Face on EKS lets an AI application answer questions using company-specific information. It can use internal documents, manuals, knowledge bases, tickets, contracts, or reports.
However, many organizations start with proprietary language model providers. They soon face a major challenge: cost per use.
Every query, every document processed, and every response generated consumes tokens. As the system grows, this payment model can become a “token tax.”
It becomes a recurring cost. It can vary. It is hard to predict. Running open-source Hugging Face models on your own AWS setup is a strong option.
You can use Amazon EKS to manage and orchestrate them.
This lets you move costs from a token-based scheme to an infrastructure-based scheme. You gain more control over scalability, security, data privacy, and model selection.
Blog Overview
- The architecture in this blog aims to cut costs. It also improves control over common data and services.
- It runs everything inside an Amazon VPC. This helps isolate and manage network components. Within this VPC, you can separate resources into public and private subnets.
- In the public area, we place exposed components such as the Application Load Balancer in a controlled manner. Sensitive services such as Amazon EKS, OpenSearch, AI inference services, and document processing remain in private subnets.
- The core of the solution is Amazon EKS, which allows you to run containerized workloads.
- In this case, EKS orchestrates services such as APIs, LLMs, embedding models, batch processes, and AI orchestration. Kubernetes offers major benefits for this type of architecture.
- It lets services scale on their own. It also isolates components, automates deployments, and adapts infrastructure as demand changes.
Hugging Face Models on EKS for RAG Architecture Components
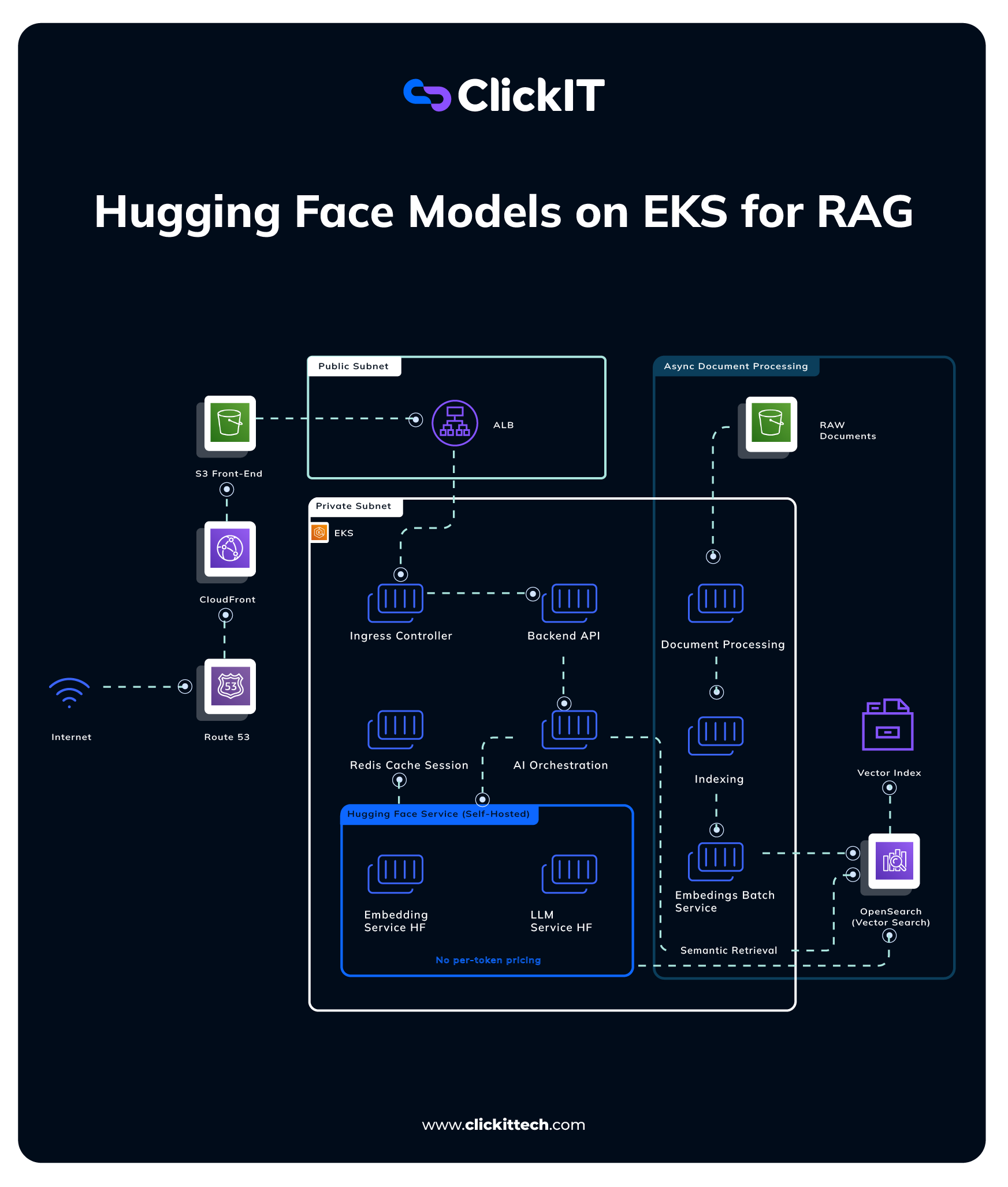
- The flow begins when the user accesses the application from the internet. Route 53 handles domain resolution and directs traffic to AWS infrastructure.
- Then, CloudFront works as a CDN to deliver the frontend fast from the nearest location. Amazon S3 stores static files like HTML, JavaScript, and images.
- When a user takes an action in the app, the request goes through the Application Load Balancer (ALB). The ALB serves as a secure entry point to the VPC. This component resides within the Public Subnet, which hosts services that receive external traffic.
- Internal and sensitive services run in the Private Subnet. This helps protect EKS, OpenSearch, and AI services. The core of the solution is Amazon EKS, which runs all services in containers using Kubernetes. Within EKS, the Ingress Controller is responsible for internally routing all requests to the correct service within the cluster.
- The Backend API manages application logic. It also talks to the AI Orchestration Service. The AI Orchestration Service coordinates the AI workflow. It receives the query and searches for relevant information. It builds the context and calls the LLM model in use.
- To speed up responses and reduce unnecessary processing, Redis Cache caches frequently accessed sessions and results.
The AI models are run using Hugging Face’s self-hosted services:
- The Hugging Face LLM Service generates responses using language models.
- The Hugging Face Embedding Service converts text into embeddings for semantic search.
- On the document flow side, we store the files in S3. Then, the Document Processing Service retrieves, cleans, and prepares the content.
- Next, the Indexing Service organizes the information, and the Embeddings Batch Service generates embeddings in large volumes.
- Finally, OpenSearch stores embeddings in the Vector Index. This lets semantic search find relevant information for each user query.
What are the cost strategies for self-hosted Hugging Face Services?
- The most important aspect of this architecture is the use of self-hosted Hugging Face services. Instead of paying for each token sent to a third-party provider, the company runs its own models on AWS. For example, businesses can deploy models such as Llama, Mistral, or other open-source models that meet business requirements. These models run as internal services within EKS.
- The same applies to embedding models. In a RAG system, embeddings are key.
- Each document and query becomes a vector for semantic search. If you pay for this process per token or per external call, costs can escalate rapidly. By running embedding models locally, the organization gains greater freedom to process large volumes of information.
This approach doesn’t mean the infrastructure is free. You still pay for resources like EC2, GPUs, storage, and networking. The difference is that the cost becomes more predictable, controllable, and easier to optimize.

How Does an Efficient Data Pipeline Improve RAG Performance?
For RAG to function correctly, the information must first be prepared. Amazon S3 stores the original documents in a designated area for raw files.
- Next, an asynchronous pipeline transforms these documents. The Document Processing Service cleans, extracts, and prepares the content. Then, the Indexing Service structures the information so users can query it efficiently.
- Subsequently, the Embeddings Batch Service generates embeddings using self-hosted Hugging Face models. OpenSearch stores these vectors, specifically in a vector index.
- When a user asks a question, the system doesn’t simply send the question to the model. First, it searches OpenSearch for the most relevant pieces of information. Then, we add these pieces to the model prompt. This ensures the response uses real, contextual company information.
How Do You Secure and Scale a RAG Architecture on EKS?

One benefit of running this architecture on AWS is improved security. You can design it with strong security practices from the start.
Critical services, such as EKS, OpenSearch, and AI models, remain on private subnets. This reduces direct internet exposure. The Application Load Balancer and well-defined network rules control external access.
For overall performance, serve the frontend from S3 and CloudFront. This allows users to quickly access the interface from different locations.
Redis helps reduce response times. It works best with repeated queries, active sessions, or data you can reuse briefly.
Furthermore, Kubernetes allows you to scale specific components. For example, if demand for inference increases, you can scale the LLM service. If the document processing workload increases, you can scale the batch workers without affecting the rest of the application.
How does the AI Orchestration Layer Work?
In this type of solution, the language model should not work in isolation. The orchestration layer transforms a simple model call into an intelligent, useful business application.
The AI Orchestration Service receives the query and runs a semantic search. It selects the most relevant context and builds the prompt.
It then sends the request to the LLM model.
Separating this logic allows for a flexible architecture. If you decide to change the LLM model tomorrow, you do not need to redesign the whole application.
To adjust the search strategy, you do not need to redesign the whole application. To improve prompts, you do not need to redesign the whole application.
To add business rules, you do not need to redesign the whole application.
This separation also facilitates observability, monitoring, testing, and continuous evolution of the system.
Running Hugging Face models on Amazon EKS for RAG solutions is a smart choice.
It helps companies use generative AI more cost-effectively, with better security and scalability.
Instead of relying only on external providers and changing token costs, this setup lets you build your own platform. It meets your business needs.
The result is a more flexible solution. It gives better control of data. It reduces dependence on vendors. It can evolve as new open source models emerge
FAQs
Running Hugging Face models on Amazon EKS allows companies to move away from unpredictable token-based pricing and gain more control over infrastructure, scalability, security, and AI model selection.
It also enables organizations to self-host open-source LLMs such as Llama or Mistral within private AWS environments.
Typically, Hugging Face models are containerized and deployed inside Kubernetes pods running on Amazon EKS. These services can include:
LLM inference services
Embedding generation services
AI orchestration APIs
Batch document processing pipelines
The infrastructure usually integrates with services such as OpenSearch, Redis, S3, CloudFront, and Application Load Balancers.
A RAG architecture combines:
Vector databases or OpenSearch
Embedding models
LLM inference services
Semantic retrieval pipelines
AI orchestration layers
The goal is to improve AI responses using company-specific data such as PDFs, knowledge bases, tickets, or internal documentation.
An AI orchestration layer coordinates:
User query intake
Semantic retrieval
Prompt construction
Business logic
LLM inference calls
This layer helps decouple retrieval, orchestration, and model execution, making enterprise AI systems easier to scale, monitor, and evolve.




