
AI MVP Development with FastAPI is becoming a practical approach for companies that want to launch AI products quickly without investing months in full-scale platforms before validating real value.
Today, many organizations are exploring artificial intelligence solutions, but the main challenge is speed. It depends on how fast they can test them in production-like environments.
Instead of building a full system on day one, aim to create an MVP. This lets teams test use cases with real users, improve quickly, and scale based on real feedback.
However, this is where many AI initiatives stall. Not due to lack of vision, but because infrastructure becomes a bottleneck. Manually configuring cloud services, managing permissions, connecting components, and preparing environments for deployment introduce delays, increase complexity, and create technical debt. Manual infrastructure is not only slow, but it’s also difficult to replicate and prone to errors.
A more effective way to build an AI MVP with FastAPI is to use it as the service layer. Add RAG to provide context-aware responses. Use IaC on AWS to automate deployment.
This architecture enables teams to move from idea to a production-ready prototype in days instead of months, building a solid, scalable foundation from the very beginning while reducing operational friction.
Why FastAPI and RAG for your AI MVP Development?

FastAPI: Why it’s best for asynchronous auto-generated documentation?
When approaching AI MVP Development with FastAPI, choosing the right technologies is critical to move fast without compromising scalability. FastAPI and Retrieval-Augmented Generation (RAG) work well together to build production-ready AI prototypes in days, not months.
FastAPI is a modern Python framework for building high-performance APIs quickly and efficiently. For an AI MVP, this is essential. At this stage, you don’t need a complex platform. You need a reliable service that can receive requests, run AI logic, and return consistent responses.
One of its biggest advantages is its native support for asynchronous operations. In practice, this helps your app handle calls to external services efficiently. These services can include LLMs, vector databases, or cloud APIs.
This is especially important in FastAPI RAG implementations on AWS, where multiple components interact in real time.
Another key benefit is automatic API documentation. FastAPI generates interactive documentation (Swagger/OpenAPI) out of the box, enabling faster collaboration between backend, frontend, QA, and product teams.
For early-stage AI products, this significantly accelerates development cycles and reduces friction.
From a business perspective, FastAPI reduces time-to-market. From a technical standpoint, it provides a clean, maintainable, and scalable architecture. And from a product perspective, it helps teams launch a pro AI service without overengineering at the start.
RAG supports this by enabling your AI MVP to generate responses using your own data, not just pretrained models. This improves accuracy, relevance, and trust, especially for document processing, internal knowledge bases, and customer support automation.
Together, FastAPI and RAG provide a flexible base for building AI apps. These apps are fast to deploy and can scale as the product grows.
Read our blog, LangChain vs LlamaIndex for RAG applications
Why is RAG Better for MVPs than fine-tuning?
RAG It’s based on a simple but powerful idea. Instead of fully retraining or tuning a model with your data, first find relevant content in your documents. Then use that content as context to generate a response.
- In an MVP, this makes RAG a particularly attractive alternative to fine-tuning. It needs less upfront investment.
- It lets you use your own data.
- It helps reduce delusions by using relevant business content.
In short, if a company already has manuals, policies, FAQs, technical documents, procedures, or knowledge bases, RAG helps. It turns that content into an intelligent experience. It does this without launching a complex model training project.
This offers several advantages.
- Time to market is much faster because you don’t need a full training pipeline to deliver value.
- The system relies on business-specific information, not just general model knowledge, making the responses more useful for real-world scenarios.
- The initial cost is usually more manageable, which is crucial when an organization wants to validate a product or use case before making a larger investment.
The Strategic Advantage: FastAPI, RAG, and AWS
The combination of FastAPI, RAG, AWS, and IaC is not just the sum of its parts; it’s valuable in the way they work together.
In practice, this allows you to build a functional solution without unnecessary complexity, while simultaneously providing a solid foundation for future growth. In other words, it’s not a hastily assembled demo, but a serious MVP.
For a company looking to launch quickly, this shortens the distance between idea and validation. For a technical team, it reduces operational chaos.
And for those offering DevOps or Cloud Engineering services, it represents a very clear value proposition: helping their clients build a useful, deployable, and repeatable AI MVP from the start.
Read our blog FastAPI vd Flask
FastAPI RAG implementation on AWS Architecture Diagram
The diagram presents a complete architecture deployed on AWS and managed with Terraform. It includes the access layer, the API, the AI backend, the RAG pipeline, DevOps automation, and the security and observability components.
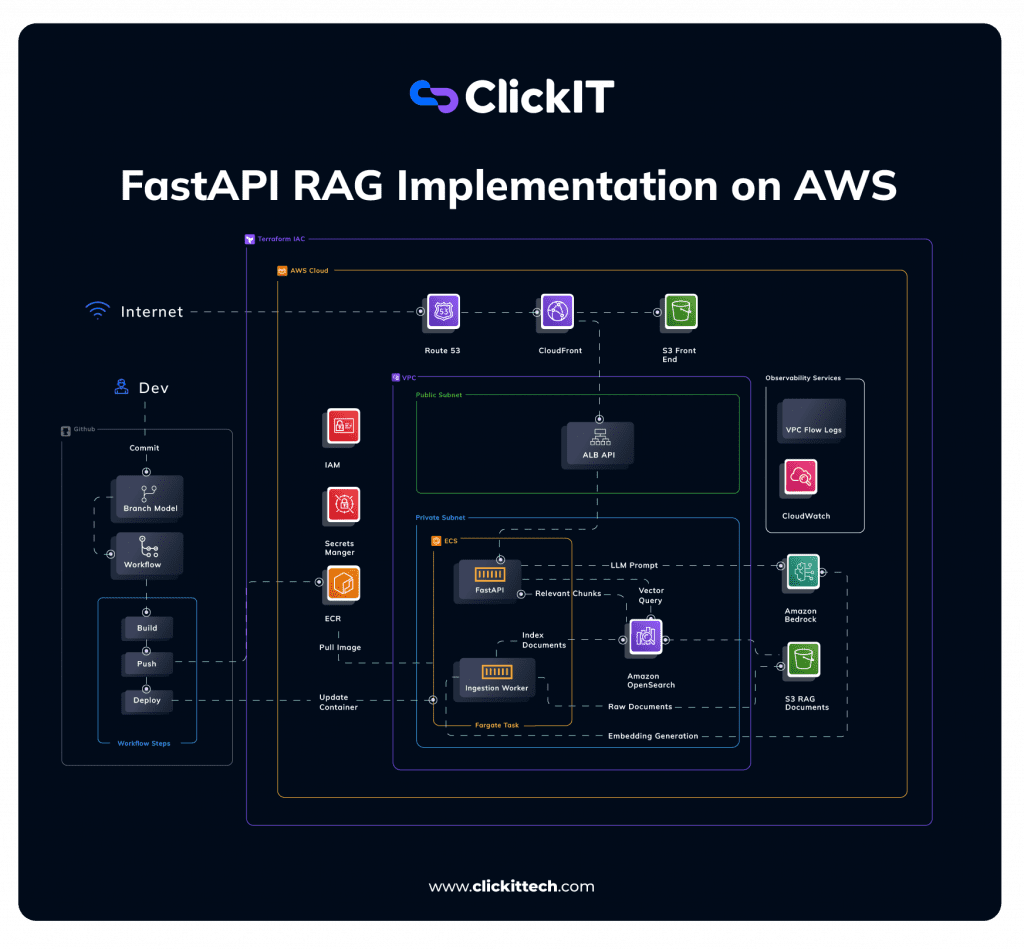
Frontend & Access Layer
- Route 53 → domain routing:
The first layer is designed to allow the user to access the solution in a stable and fast manner.
Route 53 is used to manage the domain, that is, to make the application available at a clear, professional address.
- CloudFront → CDN + performance
CloudFront functions as a CDN, which improves content delivery and user experience.
- S3 → static frontend
S3 can host the static frontend. This is useful when the MVP has a simple web interface. For example, it could be a chat or a question entry panel.
Taken together, this layer allows the product to be presented as a real solution from the outset, without the need to set up a complex frontend infrastructure.
API Layer (Entry Point)
- ALB (Application Load Balancer)
Next comes the API layer, which includes the Application Load Balancer (ALB) and the FastAPI service. This layer receives user queries and directs them to the corresponding backend logic.
- FastAPI service
This is where the intelligent use of the product begins. The user sends a question, the load balancer distributes the request, and FastAPI activates the necessary flow to generate the response.
Handles:
- User queries
- Routing requests to backend logic
This design also separates responsibilities. The interface does not need to know how the RAG engine works inside. It only needs to send the request to the right endpoint.
- Core AI Backend (Private Subnet)
The main backend runs on a private subnet. In this architecture, ECS Fargate runs the platform and hosts two key services. FastAPI serves as the inference layer, and the Ingestion Worker handles data processing.
- ECS Fargate (no server management)
Here’s a key benefit for any MVP: with Fargate, there’s no need to directly manage servers. This reduces the workload and lets the team spend more time on the product, not the infrastructure.
- Services: FastAPI (inference layer and Ingestion Worker (data processing)
The FastAPI service handles inference logic, coordinates the user query, and orchestrates the flow to ultimately generate the response.
Ingestion Worker. Instead, it prepares the information before anyone asks. It processes documents, breaks them into fragments, creates useful search representations, and readies everything for the RAG system.
Basically, one answers questions and the other prepares the knowledge so that those answers are possible.
RAG Pipeline (Core Differentiator)
At the core of the MVP is the RAG pipeline. S3 stores the source documents. OpenSearch runs the vector search. Bedrock uses the language model to generate the final response.
The workflow works like this. Documents are ingested and converted into embeddings. Those embeddings are stored in OpenSearch. When a question arrives, the system runs a vector search. It finds the most relevant fragments. Finally, those fragments are sent as context to the Bedrock model. The model then generates the answer.
In simpler terms, the system first organizes and prepares documents so they can be found accurately later. When a user asks a question, it does not answer blindly. It first searches the available content. It finds the most useful parts. Then it uses them to build a more contextual response.
This allows the MVP to offer value from very early stages. It’s not just about launching “a chatbot,” but about enabling a tool capable of accessing real business knowledge.

DevOps & Automation Layer
The DevOps and automation layer is key. Many MVPs can be built, but fail at deployment. They also struggle to maintain changes or replicate environments.
At this point, GitHub Actions runs CI/CD pipelines that automate deployments. ECR serves as a Docker image registry. Terraform defines infrastructure as code, so the environment is repeatable and easier to manage.
Thanks to this, every change to the application can follow a controlled and repeatable process. The result is fewer manual errors, faster release of new versions, and a more solid foundation for growth.
From a business perspective, this layer is also very important. Many companies manage to build demos, but they stop when it comes to deploying, upgrading, or replicating environments.
That’s where DevOps and Cloud Engineering cease to be an add-on and become a core part of the value proposition.
Security & Observability
Finally, do not defer the security and observability layer. This is vital if the prototype uses real data. It also helps if you must present a serious solution from the start.
Services like IAM allow access control, Secrets Manager helps manage credentials securely, and CloudWatch, along with VPC Flow Logs provides monitoring and visibility into system behavior.
This layer helps the MVP not only function but also operate, maintain, and scale with greater confidence.
How to Deploy an AI MVP Fast with FastAPI RAG Service in AWS?
Step 1: Define Infrastructure with Terraform
The first step to quickly deploy this MVP is to define the infrastructure with Terraform: VPC, subnets, ALB, ECS, OpenSearch, and S3.
Although it may seem like a purely operational step, it actually sets the standard for the project’s quality from the outset. When the infrastructure is defined as code, it becomes versioned, documented, and ready to be replicated in different environments. This facilitates changes, reduces inconsistencies, and improves technical traceability.
For a company, this means less reliance on manual configurations. For a DevOps team, it means more control and less… drift between environments.
Step 2: Build Your FastAPI Service
The next step is to build the service in FastAPI. This phase is not about building a huge API. It is about designing a few clear endpoints. Use one to receive queries. Use another to check service health. In some cases, add one more for support tasks.
FastAPI is especially useful here because it accelerates development and facilitates testing from the outset. It also generates interactive documentation that enables endpoint testing from the outset, accelerating both system development and validation.
Step 3: Implement the RAG Pipeline
Next comes the implementation of the RAG pipeline. This involves developing the ingestion worker that processes documents, generates embeddings, and stores them in OpenSearch.
This point matters a lot. Response quality depends on the model. It also depends on how well you prepare the document base. If the ingestion process is well-designed, the system will retrieve better fragments and respond more accurately. If it is poorly implemented, the user will perceive that the assistant cannot find useful information.
It then connects to Amazon Bedrock to use a language model in generating already contextualized responses.
Step 4: Connect to Amazon Bedrock
This greatly simplifies the path to the MVP, because the team doesn’t need to deploy or manage complex models on its own. Instead of spending time on that infrastructure, it can focus on the use case, the quality of the context, and the product experience.
For companies looking to experiment with applied AI, Bedrock lowers barriers to entry and accelerates implementation.
Step 5: Automate with CI/CD
The next step is to automate the cycle with CI/CD. With GitHub Actions, you can build the container, publish it to ECR, and deploy it to ECS following a defined workflow.
This transforms a technical project into an operational solution. There’s no longer a reliance on manual processes to deploy changes, and each release can follow a repeatable and controlled chain.
That detail is especially valuable when the goal is not just to show a prototype, but to lay a real foundation for growth.
Step 6: Deploy Frontend
Finally, the frontend is deployed to S3 and CloudFront, with the ALB connecting it to the API.
This step completes the user experience. It’s no longer just a functional backend, but an interface from which the use case can be tested directly.
And that is, in essence, what an MVP needs: not only to exist technically, but to be usable to validate whether it actually solves a problem.
When Should You Use This Approach?
A company can use this architecture to build:
- internal AI tools
- knowledge assistants
- document intelligence systems
- Early-stage AI products
In each case, FastAPI, RAG, and AWS help you move fast. You can make progress without building a huge platform first.
However, this architecture is not always the best choice.This can apply to ultra-low-latency real-time systems.It can also apply to custom machine learning pipelines.
That does not mean the architecture is bad. Instead, it is built for a specific set of needs. It supports fast validation. It relies on proprietary documentation. It uses managed services to reduce friction.
If the use case needs very low latency or a highly specialized model from the start, you may need a different approach.
If a company wants to launch a fast AI MVP with a strong technical base, this architecture is a great place to start.
FastAPI simplifies the service layer. RAG helps generate useful responses using proprietary data. AWS offers managed services that speed up deployment. Terraform makes everything repeatable and easier to maintain.
FAQs
AI MVP Development with FastAPI is the process of building a minimal, functional AI product using FastAPI as the API layer. It allows teams to quickly validate AI use cases, such as chatbots, knowledge assistants, or document processing systems, without investing in a full-scale platform from the start.
FastAPI is ideal for AI MVPs because it enables fast development of high-performance APIs. Its support for asynchronous operations makes it efficient for integrating with LLMs, vector databases, and cloud services. Additionally, its automatic documentation speeds up collaboration and testing.
RAG is an approach that retrieves relevant information from your own data and uses it to generate more accurate responses. It is important for AI MVPs because it reduces hallucinations, improves relevance, and avoids the need for expensive model fine-tuning.
A FastAPI RAG implementation on AWS typically includes FastAPI as the API layer, Amazon S3 for document storage, a vector database like OpenSearch for retrieval, and a language model (such as Amazon Bedrock) for generating responses. IaC automates deployment and ensures scalability.
Using FastAPI, RAG, and AWS Infrastructure as Code, teams can build and deploy an AI MVP in days or weeks instead of months. Automation reduces manual setup and allows faster iteration and validation.




